
【转载】知乎文章:机器翻译发展简史
一、一图胜千言——主要发展节点
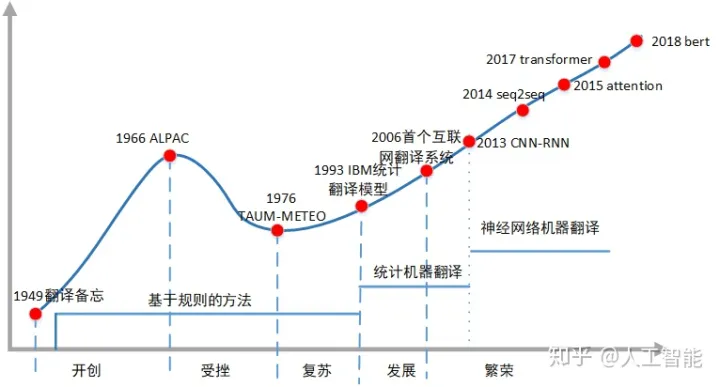
二、6大发展时期
1. 机器翻译的提出(1933-1949)
机器翻译的研究历史最早可以追溯到 20 世纪30年代。1933年,法国科学家 G.B. 阿尔楚尼提出了用机器来进行翻译的想法。
1946 年,世界上第一台现代电子计算机 ENIAC 诞生。随后不久,信息论的先驱、美国科学家 Warren Weaver 于 1947 年提出了利用计算机进行语言自动翻译的想法。1949 年,Warren Weaver 发表《翻译备忘录》[1],正式提出机器翻译的思想。
2. 开创期(1949-1964)
1954 年,美国乔治敦大学在 IBM 公司协同下,用 IBM-701 计算机首次完成了英俄机器翻译试验。IBM 701 计算机有史以来第一次自动将 60 个俄语句子翻译成了英语。但是没人提到这些翻译得到的样本是经过精心挑选和测试过的,从而排除了歧义性。
这一时期,美国与苏联两个大国出于对军事的需要,投入了大量资金用于机器翻译。集中在英文与俄文的语言配对翻译,翻译的主要对象是科学和技术上的文件,如科学期刊的文章,粗糙的翻译足以了解文章的基本内容。欧洲国家由于经济需要,也给予了相当大的重视。机器翻译于这一时期出现热潮。
3. 受挫期(1964-1975)
然而,正当一切有序推进之时,尚在萌芽中的 “机器翻译” 研究却遭受当头一棒。1964 年,美国科学院成立了语言自动处理咨询委员会 (Automatic Language Processing Advisory Committee)。委员会经过 2 年的研究,于 1966 年 11 月公布了一份名为《语言与机器》(简称 ALPAC 报告)的报告[2]。该报告全面否定了机器翻译的可行性,并宣称 “在近期或可以预见的未来,开发出实用的机器翻译系统是没有指望的”。建议停止对机器翻译项目的资金支持。受此报告影响,各类机器翻译项目锐减,机器翻译的研究出现了空前的萧条。
4. 复苏期(1975-1989)
1970中后期,随着计算机技术和语言学的发展以及社会信息服务的需求,机器翻译才开始复苏并日渐繁荣。业界研发出了多种翻译系统,例如 Weinder、URPOTRAA、TAUM-METEO 等。 其中于 1976 年由加拿大蒙特利尔大学与加拿大联邦政府翻译局联合开发的 TAUM-METEO 系统,是机器翻译发展史上的一个里程碑,标志着机器翻译由复苏走向繁荣。
5. 发展期(1993-2006)
这一时期主要是统计机器翻译。
1993 年 IBM 的 Brown 和 Della Pietra 等人提出的基于词对齐的翻译模型。标志着现代统计机器翻译方法的诞生。
2003 年Franz Och 提出对数线性模型及其权重训练方法,这篇文章提出了基于短语的翻译模型和最小错误率训练方法。对应的两篇文章Statistical phrase-based translation[3]和Minimum error rate training in statistical machine translation。[4]标志着统计机器翻译的真正崛起。
6. 繁荣期(2006-至今)
2006年,谷歌翻译作为一个免费服务正式发布,并带来了统计机器翻译研究的一大波热潮。这一研究正是Franz Och于2004年加入谷歌,领导谷歌翻译。 正是因为一代代科学家们不懈的努力,才让科幻一步步照进现实。
2013 Recurrent Continuous Translation Models[5],Nal Kalchbrenner和 Phil Blunsom提出了一种用于机器翻译的新型端到端编码器-解码器架构 。该模型使用卷积神经网络(CNN)将给定的源文本编码为连续向量,然后使用循环神经网络(RNN)作为解码器将状态向量转换为目标语言。他们的研究可视为神经机器翻译(NMT)的开端,
2014 Sequence to sequence learning with neural networks[6].是由Bengio提出的,基于encoder-decoder架构,其中encoder和decoder都是RNN结构,使用的是LSTM。这个架构也上线到Google的翻译中,翻译的质量有些可以超越人类。
2015 Neural Machine Translation by Jointly Learning to Align and Translate[7].在以往的encoder-decoder框架上加入对其的attention权重。
2017 Attention Is All You Need[8].Transformer抛弃了传统的CNN和RNN,整个网络结构完全是由Attention机制组成。Transformer的主要创新点在于multi-head、self-Attenion,基于此,transformer可以并行操作,大大加快了训练过程。
2018 BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding[9].BERT本质上是在大规模的语料上,运行自监督的方法,学习到一个好的特征表示。那么下游任务,可以BERT训练的词向量,作为输入,做一些fine-tune则可完成任务。主要通过Mask Language Model(MLM) 和 Next Sentence Prediction(NSP) 的这两个任务训练,得到词特征表示和句特征表示。
三、参考
参考论文:
[1]http://www.mt-archive.info/Weaver-1949.pdf
[2]Thierry Poibeau, “The 1966 ALPAC Report and Its Consequences,” inMachine Translation, MITP, 2017, pp.75-89.
[1]Koehn P , Och F J , Marcu D . Statistical Phrase-Based Translation[C]// Conference of the North American Chapter of the Association for Computational Linguistics on Human Language Technology. Association for Computational Linguistics, 2003.
[4]Och, Franz Josef. “Minimum Error Rate Training for Statistical Machine Translation.” ACL, 2003.
[5]Kalchbrenner, N., & Blunsom, P. (2013, October). Recurrent Continuous Translation Models. InEMNLP(Vol. 3, No. 39, p. 413).
[6]Sutskever, I., Vinyals, O., & Le, Q. V. (2014). Sequence to sequence learning with neural networks. InAdvances in neural information processing systems(pp. 3104-3112).
[7]Bahdanau, D., Cho, K., & Bengio, Y. (2014). Neural machine translation by jointly learning to align and translate.arXiv preprint arXiv:1409.0473.
[8]Vaswani A , Shazeer N , Parmar N , et al. Attention Is All You Need[J]. arXiv, 2017.
[9]Devlin J , Chang M W , Lee K , et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding[J]. 2018.
本文转载自知乎:https://zhuanlan.zhihu.com/p/223033781
转载目的在于学习,收藏。感兴趣的读者可访问原作者网页及其相关专栏文章。